

Building applications in the cloud today requires a complete paradigm shift from traditional on-premises infrastructure. The core value proposition of the cloud—elasticity, cost efficiency, and high availability—is entirely dependent on designing the application architecture for inherent scalability. A system is truly scalable when it can handle massive and unpredictable increases in workload (traffic, data volume, concurrent users) without a proportional increase in operational cost or performance degradation. Designing for scalability from the very first line of code is no longer optional; it is the fundamental requirement for surviving and thriving in the digital economy.
This extensive guide provides a deep, technical dive into the strategic principles, architectural components, and implementation best practices for building a robust, scalable cloud architecture from scratch. We will analyze the crucial differences between vertical and horizontal scaling, dissect the role of abstraction layers in achieving resilience, and detail the integration of key managed services for compute, data, and networking. This is the definitive blueprint for engineers and architects aiming to construct a cloud-native platform capable of handling global demand and unpredictable traffic spikes with unwavering performance.
1. Foundational Design Principles for Scale
Achieving true scalability requires adhering to specific architectural philosophies that prioritize distribution, statelessness, and abstraction.
A. Horizontal Scaling Over Vertical Scaling
The fundamental decision in scalable design is prioritizing horizontal scaling (scaling out) over vertical scaling (scaling up).
-
Vertical Scaling (Scaling Up): This involves increasing the resources of a single server (e.g., adding more CPU cores, RAM, or faster storage). This is simple but faces physical and economic limitations. A single machine is always a single point of failure (SPOF) and costs increase exponentially for marginal performance gains.
-
Horizontal Scaling (Scaling Out): This involves adding more, smaller instances to share the workload. This is the cornerstone of cloud scalability. It offers near-limitless capacity and eliminates single points of failure. The goal is to build a system where adding one more server instance provides a predictable, linear increase in total capacity.
B. Embracing Statelessness
For any component of the application that must be horizontally scaled, it must be stateless.
-
Definition of Stateless: A stateless component does not store any session-specific data, user information, or context on the server itself. All necessary state data (like shopping cart contents or user logins) is externalized to a separate, highly available data store (e.g., a managed database or cache).
-
Operational Benefit: When a server instance fails, it can be instantly replaced without losing active user sessions, and traffic can be routed to any available server, drastically improving resilience and load balancing efficiency.
C. Decoupling and Microservices Architecture
Highly scalable applications are built from independently deployable, loosely coupled services.
-
Decoupling: Breaking down a large, monolithic application into smaller, specialized services ensures that a failure in one service does not cascade and bring down the entire system. Communication between services should primarily be asynchronous (using queues or event streams) to prevent direct dependencies.
-
Microservices: A common architectural style where each service (e.g., User Authentication, Payment Processing, Product Catalog) is a self-contained unit managed by its own team and often using its own optimized data store. This allows different services to scale independently based on their specific demand. For instance, the Image Processing service may scale higher than the rarely used Reporting service.
2. The Compute Layer: Designing for Elasticity
The compute layer—the actual servers running the application code—must be designed to utilize the cloud’s elastic nature fully.
A. Auto-Scaling Groups (ASG)
Auto-Scaling Groups are the core mechanism for achieving horizontal scaling in the cloud compute layer.
-
Functionality: An ASG monitors the load on a defined group of compute instances (e.g., Virtual Machines or containers) and automatically adds or removes instances based on predefined metrics (e.g., average CPU utilization, request queue length, network I/O).
-
Scaling Policies:
-
Target Tracking: Scales to keep a metric at a target value (e.g., maintaining average CPU utilization at ).
-
Simple/Step Scaling: Scales based on fixed thresholds (e.g., add 2 servers when CPU hits ).
-
Scheduled Scaling: Scales up in anticipation of predictable traffic (e.g., adding capacity every Friday at 4 PM).
-
-
Health Checks: The ASG is constantly checking the health of its instances. If an instance fails a health check, it is automatically terminated and replaced, ensuring high availability.
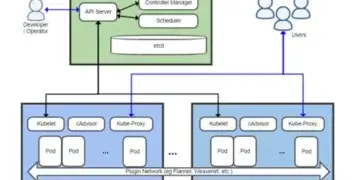
B. Containers and Orchestration
For modern, microservices-based architectures, containers managed by an orchestrator are the preferred method for compute elasticity.
-
Kubernetes (K8s): The industry standard orchestrator for containers. K8s manages the deployment, scaling, and networking of containerized applications. It automatically replaces failed containers and ensures the desired number of replicas are always running.
-
Managed Services: Utilizing fully managed container services (like Amazon EKS or Google Kubernetes Engine) removes the operational burden of managing the Kubernetes control plane itself, allowing the team to focus purely on application code and deployment.
C. Serverless Functions
For event-driven, intermittent workloads, serverless computing offers the highest degree of automatic, granular scaling.
-
Function-as-a-Service (FaaS): The provider manages all the scaling from zero instances to thousands instantly. The user pays only for the execution time (in milliseconds).
-
No Provisioning Decisions: The architecture is entirely abstracted. The developer is freed from making any auto-scaling configuration decisions, leading to maximal cost efficiency and zero idle time.
3. The Data Layer: The Scaling Bottleneck
The data layer (databases and storage) is typically the hardest component to scale. Scalable architecture necessitates choosing the right data store for the job and distributing data.
A. Relational Database Scaling Strategies
For applications that require transactional consistency and complex queries, relational databases require specialized scaling strategies.
-
Read Replicas: The most common strategy is to create one or more read replicas (copies of the primary database). All read traffic, which often accounts for or more of total database load, is distributed across the replicas, offloading the primary instance.
-
Sharding: For truly massive workloads that exceed the capacity of a single primary database, sharding is necessary. This involves splitting the data horizontally across multiple independent database instances (shards), with each shard hosting a unique subset of the data (e.g., data for customers A-M on Shard 1, N-Z on Shard 2). This adds complexity but enables limitless scaling.
-
Managed DBaaS: Utilizing managed database services (like Amazon RDS, Azure SQL Database) abstracts away the complexity of managing patches, backups, and physical replication, significantly simplifying the scaling process.
B. Leveraging Non-Relational (NoSQL) Databases
For use cases requiring massive scale, flexibility, and high read/write throughput, NoSQL databases are essential.
-
Horizontal Scale by Design: NoSQL databases (Document, Key-Value, Columnar) are inherently designed for horizontal scaling, automatically distributing data across numerous nodes.
-
Use Cases:
-
Key-Value Stores (Caching): Used to store session data, user profiles, or frequently accessed product data in memory for extremely fast retrieval, drastically reducing the load on the relational database.
-
Document Stores: Used for flexible data structures like user generated content, product catalogs, or logging systems where schemas evolve rapidly.
-
C. Content Delivery Network (CDN) for Static Assets
Offloading static content is the easiest and most effective way to scale the web front-end.
-
Caching at the Edge: A CDN caches static assets (images, JavaScript, CSS, videos) at thousands of globally distributed Edge Locations physically close to the end-users. This drastically reduces latency and removes the load of serving these assets entirely from the application servers.
-
Global Resilience: By distributing traffic across the globe, the CDN provides an essential layer of defense against high-volume traffic spikes and DDoS attacks.
4. The Networking and Security Layer
The network layer must be configured to intelligently route traffic and maintain security under massive load.
A. Load Balancing and Distribution
Load Balancers are the traffic managers, distributing client requests efficiently across the scalable fleet of compute resources.
-
Health Checks: The Load Balancer constantly performs health checks on backend instances. If an instance is deemed unhealthy, the Load Balancer automatically removes it from the rotation, ensuring requests only go to live servers.
-
Layer 7 Routing: Advanced Load Balancers can route traffic based on application-layer information (Layer 7), such as the URL path or header information. This is critical in microservices architecture, allowing traffic for
/api/paymentsto be routed to the Payment Service ASG, while traffic for/api/productsgoes to the Product Service ASG.
B. Network Segmentation with VPC
Proper network segmentation is critical for security and managing scale.
-
Private Subnets: Compute resources that do not need direct public internet access (e.g., application servers, databases, caches) must be placed in Private Subnets. This ensures they cannot be directly accessed from the internet, protecting them from unauthorized attacks.
-
Public Subnets: Only resources that need to be directly exposed (e.g., Load Balancers, CDN endpoints) should reside in Public Subnets.
-
Security Groups: Acting as virtual firewalls, security groups must be configured with the Principle of Least Privilege, allowing traffic only on specific ports and only from trusted sources (e.g., allowing port 80/443 traffic only from the Load Balancer).
5. Automation and Observability
A scalable architecture is too complex to manage manually; it requires automation and continuous monitoring.
A. Infrastructure as Code (IaC)
IaC is mandatory for maintaining consistency and repeatability across the entire architecture.
-
Idempotency: IaC tools (like Terraform or CloudFormation) allow the entire cloud environment to be defined in code. Running the code produces the same environment every time, ensuring that the development, staging, and production environments are identical, which is crucial for predictable scaling behavior.
-
Version Control: Infrastructure code is stored in version control (Git), allowing for easy rollbacks and auditing of every change made to the production environment, increasing stability and security.
B. Centralized Logging and Monitoring
Scalable, distributed systems generate massive volumes of data (logs, metrics). This data must be managed centrally to troubleshoot performance bottlenecks or failures during a scale-up event.
-
Metrics Collection: Cloud monitoring services (like CloudWatch, Azure Monitor) automatically collect performance metrics (CPU, latency, queue depth) from all services. Setting up custom metrics that track application-specific performance (e.g., transactions per second) is critical.
-
Centralized Logging: All application and infrastructure logs must be streamed to a central, searchable log aggregation platform. This allows engineers to rapidly diagnose which of the potentially hundreds of active instances is causing a problem.
-
Alerting and Automation: Automated alerts must be configured for critical thresholds. These alerts should not just notify an engineer, but often trigger automated remediation actions (e.g., scaling up resources, isolating a faulty service).
6. Design for Failure and Resilience
True scalability includes the ability to maintain service integrity during component failure. The entire architecture must be designed with the assumption that failure is inevitable.
A. Multi-Region and Multi-AZ Deployment
Geographical redundancy is the final layer of resilience.
-
Availability Zones (AZs): The architecture must be deployed across at least two (ideally three) isolated Availability Zones within a single region. These AZs are physically separate data centers with independent power, cooling, and networking. If one AZ fails, the Load Balancer automatically routes traffic to the healthy AZs, ensuring continuous service.
-
Regional Disaster Recovery: For the highest level of resilience, critical components can be replicated across separate geographic regions. While costly, this protects against catastrophic events that affect an entire region.
B. Timeouts, Retries, and Circuit Breakers
Inter-service communication must be hardened to prevent service failures from cascading.
-
Timeouts: Every service call (API call, database query) must have a strict timeout defined. If the call exceeds the limit, the connection is dropped, preventing the calling service from waiting indefinitely and exhausting its own resources.
-
Retries: Simple, transient errors (like network glitches) should be handled with a limited number of exponential backoff retries—waiting longer between each attempt—to prevent overwhelming the failing service.
-
Circuit Breakers: A circuit breaker pattern monitors a service’s failure rate. If the rate exceeds a threshold, the circuit “opens,” meaning all subsequent requests to that service are instantly failed without even attempting a connection. This prevents the unhealthy service from dragging down the entire application.
7. Cost Optimization at Scale

In the cloud, scaling must be coupled with rigorous cost management to remain economically viable.
A. Rightsizing and Reserved Instances
Intelligent resource sizing is crucial for minimizing waste.
-
Rightsizing: Continuously monitoring actual resource utilization (CPU, memory) and resizing VMs to match the workload’s true requirements, eliminating over-provisioning.
-
Reserved Instances (RIs): For the baseline capacity that is expected to run 24/7, purchasing Reserved Instances or Savings Plans locks in resources at a significantly discounted rate (up to off on-demand pricing), converting the steady-state OpEx into a more predictable, discounted cost.
B. Utilizing Managed Services
Leveraging Platform as a Service (PaaS) and Software as a Service (SaaS) is a hidden scaling and cost advantage.
-
Operational Cost Savings: Managed services (e.g., managed databases, managed load balancers) remove the labor cost and complexity of scaling, patching, and maintaining those components internally, allowing the team to focus resources on the core application logic.
-
Built-in Scalability: PaaS services are inherently designed to scale automatically up to massive limits without manual intervention, ensuring the application can grow without being constrained by infrastructure.
Conclusion: A Continuous Process
Building scalable cloud architecture from scratch is an ongoing commitment to a set of core principles: horizontal scaling, statelessness, decoupling, and designing for failure. By implementing the fundamental components—Auto-Scaling Groups, advanced Load Balancing, distributed NoSQL databases, and IaC—an organization can build a platform that harnesses the immense power of the public cloud.
The architecture must be dynamic, monitored through centralized observability tools, and governed by strict automation. True success is not just reaching the target scale, but maintaining performance consistency and cost efficiency as the workload fluctuates unpredictably. The most scalable architecture is the one that minimizes manual intervention, allowing the system to manage its own growth and resilience autonomously. Scalability is an architecture mindset, not just a feature.





{kind=link}